MapReduce 简介
在当今以数据为驱动的市场中,算法和应用程序全天候收集有关人员、流程、系统和组织的数据,导致数据量巨大。然而,挑战在于如何快速高效地处理这些海量数据,同时不牺牲有意义的洞察。
这就是MapReduce编程模型发挥作用的地方。MapReduce最初由Google用于分析其搜索结果,由于其能够并行处理数TB的数据并快速获得结果,因此获得了巨大的流行。
什么是MapReduce?
MapReduce是在Hadoop框架内用于访问存储在Hadoop文件系统(HDFS)中的大数据的编程模型或模式。
它是Hadoop框架的核心组件,对Hadoop框架的运作至关重要。
MapReduce通过将PB级的数据分割成更小的块,并在Hadoop普通服务器上并行处理它们,从而实现并发处理。最终,它将来自多个服务器的所有数据聚合,将合并后的输出返回给应用程序。
例如,一个拥有20,000台廉价普通服务器的Hadoop集群,每个服务器有256MB的数据块,可以同时处理大约5TB的数据。与顺序处理如此大量的数据集相比,这减少了处理时间。
有了MapReduce,不是将数据发送到应用程序或逻辑所在的服务器,而是在数据已经存在的服务器上执行逻辑,以加快处理速度。
数据访问和存储是基于磁盘的——输入通常存储为包含结构化、半结构化或非结构化数据的文件,输出也存储在文件中。
MapReduce曾经是唯一可以从HDFS检索数据的方法,但现在情况不再如此。今天,还有其他基于查询的系统,如Hive和Pig,它们使用类似SQL的语句从HDFS检索数据。然而,这些通常与使用MapReduce模型编写的作业一起运行。那是因为MapReduce有其独特的优势。
MapReduce如何工作
MapReduce的核心是两个函数:Map和Reduce。它们是顺序执行的。
-
Map
函数从磁盘接收输入作为
<key,value>
对,处理它们,并产生另一组中间
<key,value>
对作为输出。
-
Reduce
函数也接收输入作为
<key,value>
对,并产生
<key,value>
对作为输出。
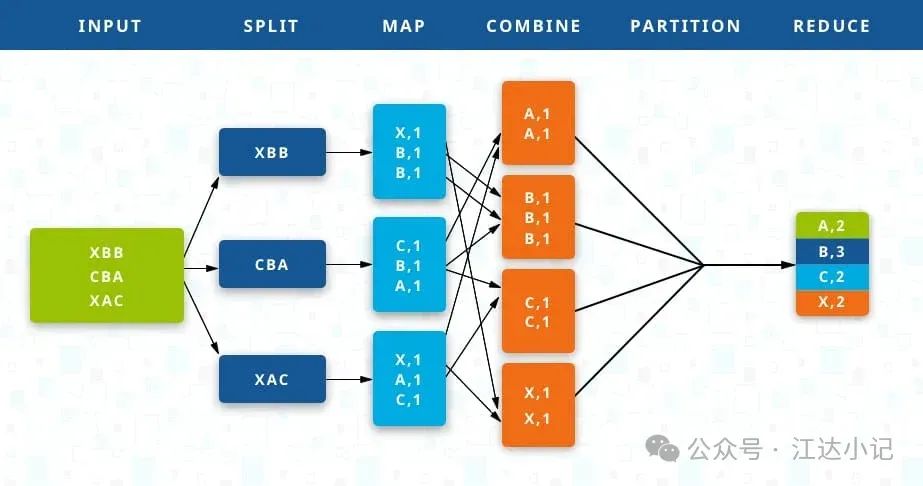
根据用例,键和值的类型会有所不同。所有输入和输出都存储在HDFS中。虽然map是过滤和排序初始数据的必经步骤,但reduce函数是可选的。
<k1,
v1
-> Map() -> list(
<k2,
v2
)
<k2,
list(v2)
-> Reduce() -> list(
<k3,
v3
)
Mapper和Reducer分别是运行Map和Reduce函数的Hadoop服务器。这些可以是相同的服务器,也可以是不同的服务器。
Map
输入数据首先被分割成更小的块。每个块然后被分配给一个mapper进行处理。
例如,如果一个文件有100条记录需要处理,100个mapper可以一起运行,每个处理一条记录。或者,也许50个mapper可以一起运行,每个处理两条记录。Hadoop框架根据要处理的数据大小和每个mapper服务器上可用的内存块来决定使用多少mapper。
Reduce
所有mapper完成处理后,框架会将结果进行洗牌和排序,然后传递给reducers。只要mapper还在进行中,reducer就不能开始。所有具有相同键的map输出值被分配给单个reducer,然后聚合该键的值。
Combine和Partition
Map和Reduce之间有两个中间步骤。
Combine
是一个可选过程。Combiner是在每个mapper服务器上单独运行的reducer。它在将数据传递到下游之前,进一步减少每个mapper上的数据到简化形式。
这使得洗牌和排序变得更容易,因为要处理的数据更少。通常,combiner类被设置为reducer类本身,因为reduce函数中的累积和关联函数。然而,如果需要,combiner也可以是一个单独的类。
Partition
是将由mapper产生的
<key,
value
对转换为另一组
<key,
value
对以输入reducer的过程。它决定了如何将数据呈现给reducer,并且还将其分配给特定的reducer。
默认的分区器确定由mapper产生的键的哈希值,并根据这个哈希值分配分区。分区的数量与reducer的数量一样多。因此,一旦分区完成,每个分区的数据就被发送到特定的reducer。
