Faiss向量相似度搜索库介绍
Faiss
Faiss 是一个用于高效相似性搜索和密集向量聚类的库。它包含的算法可以在任意大小的向量集合中进行搜索,甚至包括那些可能无法完全放入 RAM 的数据集。此外,它还提供了用于评估和参数调整的支持代码。Faiss 是用 C++ 编写的,并且为 Python(2 和 3 版本)提供了完整的包装器。其中一些最有用的算法还实现了 GPU 加速。Faiss 主要由 Meta AI Research 开发,并得到了外部贡献者的帮助。
什么是相似性搜索?
给定一组维度为 (d) 的向量 ({x_1, \dots, x_n}),Faiss 会在 RAM 中构建一个数据结构。在构建完该结构后,当给定一个新的维度为 (d) 的向量 (x) 时,它会高效地执行以下操作:
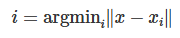
其中 || || 表示欧几里得距离(L^2)。
在 Faiss 的术语中,这个数据结构被称为“索引”,它是一个具有“添加”方法的对象,用于添加 (x_i) 向量。需要注意的是,(x_i) 的维度被假定为固定不变的。
计算 argmin 的过程就是索引上的“搜索”操作。
这便是 Faiss 的全部内容。此外,它还可以:
-
返回的不仅仅是最近邻,还可以返回第二近、第三近……第 (k) 近的邻居。
-
同时搜索多个向量,而不是一次只搜索一个(批量处理)。对于许多索引类型来说,这比逐个搜索向量要快。
-
在速度和精度之间进行权衡,例如,使用一种速度提高 10 倍或内存使用量减少 10 倍的方法,但可能会有 10% 的时间给出错误的结果。
-
执行最大内积搜索 (argmax_i < x, x_i >),而不是最小欧几里得搜索。它还对其他距离(如 L1、Linf 等)提供了有限的支持。
-
返回所有在查询点给定半径范围内的元素(范围搜索)。
-
将索引存储在磁盘上,而不是 RAM 中。
-
索引二进制向量,而不是浮点向量。
-
根据向量 ID 的谓词忽略索引向量的一个子集。
安装
推荐通过 Conda 安装 Faiss:
1 | $ conda install -c pytorch faiss-cpu |
$ conda install -c pytorch faiss-gpu
需要注意的是,应该安装其中的一个包,而不是同时安装两个,因为后者是前者的超集。
