什么是图像嵌入(image embedding)
在计算机视觉领域,有一个核心概念:让计算机能够理解视觉输入。这一概念可以分解为许多任务:识别图像中的物体、对图像进行聚类以找出异常值、创建用于搜索大量视觉数据的系统等。图像嵌入(embedding)是许多视觉任务的核心,从聚类到图像比较,再到为大型多模态模型(LMMs)提供视觉输入,都离不开它。
在本指南中,我们将介绍什么是图像嵌入、它们如何被使用,以及 CLIP,这是一个流行的计算机视觉模型,你可以用它来生成图像嵌入,从而构建一系列应用程序。
不再多说,让我们开始吧!
嵌入入门:什么是图像嵌入?
图像嵌入是对图像的数值表示,它编码了图像内容的语义。嵌入是通过计算机视觉模型计算得出的,这些模型通常使用大量成对的文本和图像数据进行训练。这种模型的目标是构建图像与文本之间关系的“理解”。
这些模型使你能够为图像和文本创建嵌入,然后可以将它们进行比较,用于搜索、聚类等。查看我们关于使用图像嵌入进行聚类的文章,了解该主题的教程。
嵌入与图像的原始形式不同。图像文件包含 RGB 数据,它精确地说明了每个像素的颜色。嵌入则编码了代表图像内容的信息。嵌入的原始形式是无法理解的,就像将图像读作一系列数字时一样。只有当你使用嵌入时,它们才开始变得有意义。
考虑以下这张图像:

这张图像包含一个装满水果的碗。图像嵌入将对这些信息进行编码。然后,我们可以将图像嵌入与类似“水果”的文本嵌入进行比较,以查看“水果”这一概念与图像内容的相似程度。我们可以取两个提示词,如“水果”和“蔬菜”,看看它们各自与图像的相似度。最相似的提示词被认为是图像内容最具代表性的。
接下来,我们来讨论 CLIP,这是一个由 OpenAI 开发的流行图像嵌入模型,然后通过一些嵌入示例来看看你可以用嵌入做什么。
CLIP 是什么?
CLIP(Contrastive Language-Image Pretraining,对比语言-图像预训练)是由 OpenAI 开发并于 2019 年发布的多模态嵌入模型。CLIP 使用超过 4 亿对图像和文本进行训练。你可以用 CLIP 计算图像和文本的嵌入,并将图像嵌入与文本嵌入进行比较。
CLIP 是一个零样本模型,这意味着模型不需要任何微调就可以计算嵌入。对于分类任务,你需要为每个可能的类别计算一个文本嵌入,为你要分类的图像计算一个图像嵌入,然后使用余弦相似度等距离度量将每个文本嵌入与图像嵌入进行比较。相似度最高的文本嵌入就是与图像最相关的标签。
使用嵌入对图像进行分类
图像分类是一项任务,目标是从有限的类别中为图像分配一个或多个标签。例如,考虑以下这张停车场的图像:

我们可以将这张图像与“停车场”和“公园”这两个词进行比较,看看它们的相似度。让我们将图像通过 CLIP(一个流行的嵌入模型)进行处理,并比较图像与每个提示词的相似度。CLIP 是一个由嵌入驱动的零样本分类模型。这意味着你可以使用嵌入对图像进行分类,而无需训练一个微调模型。
以下是嵌入比较的置信度结果。这些结果显示了 CLIP 认为给定文本标签与图像内容匹配的置信度。
-
停车场:0.99869776
-
公园:0.00130221
由于类别“停车场”的置信度最高,我们可以假设图像更接近停车场而不是公园。在上述示例中,置信度是通过最接近 1 的数值来衡量的。你可以将每个值乘以 100 来得到百分比。我们使用 OpenAI CLIP GitHub 仓库中的示例代码来运行计算。
使用嵌入对视频场景进行分类
视频包含一系列帧。你可以将每一帧视为一个独特的图像,可以对其进行分类。你可以将视频中的帧通过 CLIP 进行处理,以实现零样本视频分类。你可以查看视频中的每一帧,或者每隔 n 帧查看一次,以确定它们与文本提示列表中的相似度。
以下视频展示了 CLIP 正在运行,以确定视频帧与文本提示“咖啡杯”的相似度:

你可以使用 CLIP 来识别视频中何时出现某个物体。例如,如果 CLIP 确定视频帧中包含一个人,你就可以添加一个标签,说明视频中有人。或者你可以统计包含猫的帧的数量,以便跟踪视频中哪些场景有猫。如果你想在自己的数据上尝试,可以查看我们关于使用 CLIP 分析视频的端到端教程。
使用 CLIP 对视频进行分类有诸多应用,包括识别视频中何时出现某个特定概念,以及判断视频是否适合工作场景(通过检测是否存在暴力或色情内容)。
使用嵌入对图像进行聚类
嵌入可以用于对图像进行聚类。你可以将图像聚类到一个固定数量的组中(例如三个组),也可以在没有固定聚类数量的情况下对嵌入进行聚类。在前一种情况下,你可以在有限的聚类中识别图像之间的模式;在后一种情况下,你可以根据嵌入计算数据集中图像之间的距离。聚类通常用于异常值检测,目标是找出足够不相似的图像。
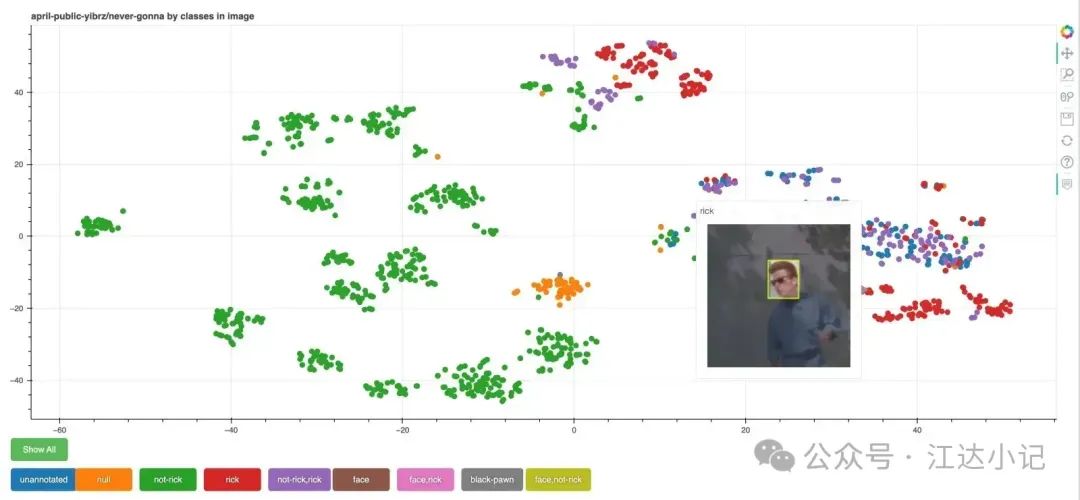
k-means 聚类通常用于将嵌入聚类到固定数量的类别中。有许多算法可以让你根据嵌入将图像聚类到不确定数量的聚类中。DBSCAN 就是一个这样的例子。我们有一篇指南,介绍了如何对图像嵌入进行聚类。
以下图像展示了使用 CLIP 对图像数据集进行聚类,并使用 Bokeh 进行可视化:
使用嵌入进行图像搜索
在上文中,我们介绍了两个概念:
-
文本嵌入。
-
图像嵌入。
这两个值都是由嵌入模型计算得出的。你可以比较文本和图像嵌入,以查看文本与图像的相似度。你可以将嵌入保存在一个特殊的数据库中,称为向量数据库(用于存储嵌入),以便在图像和文本嵌入之间进行高效搜索。这种高效的搜索使你能够构建“语义”图像搜索引擎。
语义图像搜索引擎是一种可以通过自然语言概念进行查询的搜索引擎。例如,你可以输入“猫”来查找数据集中所有的猫,或者输入“安全帽”来查找与安全帽相关的图像。过去,构建这样的搜索引擎成本过高且技术上具有挑战性。有了嵌入和向量数据库,构建一个运行快速的图像搜索引擎成为可能。
Roboflow 平台使用语义搜索,方便你在数据集中查找图像。以下视频展示了一个示例,通过提供自然语言查询来检索数据集中的图像:
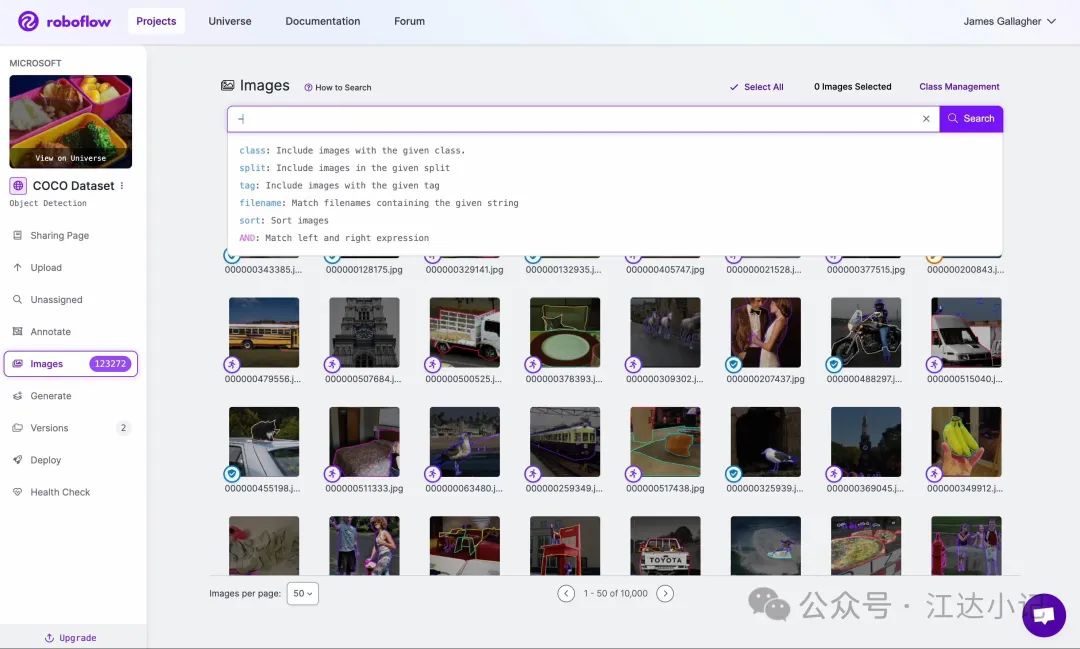
你可以尝试在 Roboflow Universe 上查询 COCO 数据集,体验由图像嵌入驱动的语义搜索。
结论
嵌入是对图像内容的数值化、语义化表示。图像嵌入在现代视觉任务中有广泛的应用。你可以使用嵌入对图像进行分类、对视频帧进行分类、对图像进行聚类以找出异常值、在图像文件夹中进行搜索等。在上文中,我们详细讨论了这些用例。
如果你想了解更多关于计算嵌入的信息,请查看我们关于使用 Roboflow 推理与 CLIP 进行分类的指南。Roboflow 推理是一个开源服务器,用于部署视觉模型,为全球大型企业的数百万次 API 调用提供支持。你也可以使用 Roboflow 的托管推理解决方案,它由相同的技术驱动,用于计算用于视觉应用的嵌入。
