在计算机视觉中使用嵌入和聚类
翻译自
https://blog.roboflow.com/embeddings-clustering-computer-vision-clip-umap/
嵌入在自然语言处理(NLP)领域已经成为一个热门话题,并且在计算机视觉中也越来越受到关注。这篇博客文章将通过研究图像聚类、评估数据集质量和识别图像重复项,探讨嵌入在计算机视觉中的应用。
我们创建了一个Google Colab笔记本,你可以在阅读这篇博客文章的同时在另一个标签页中运行它,让你能够实时实验和探索这里讨论的概念。让我们开始吧!
使用像素亮度对MNIST图像进行聚类
在我们跳到涉及OpenAI CLIP嵌入的例子之前,让我们先从一个不太复杂的例子开始——根据像素亮度对MNIST图像进行聚类。

从MNIST数据集中随机选择的图像的示意图。
MNIST数据集包含60,000张28x28像素的灰度手写数字图像。由于灰度图像中的每个像素可以用一个值来描述,因此每张图像有784个值(或特征)来描述。我们的目标是使用t-SNE和UMAP将维度减少到三个,以便在三维空间中显示图像聚类。
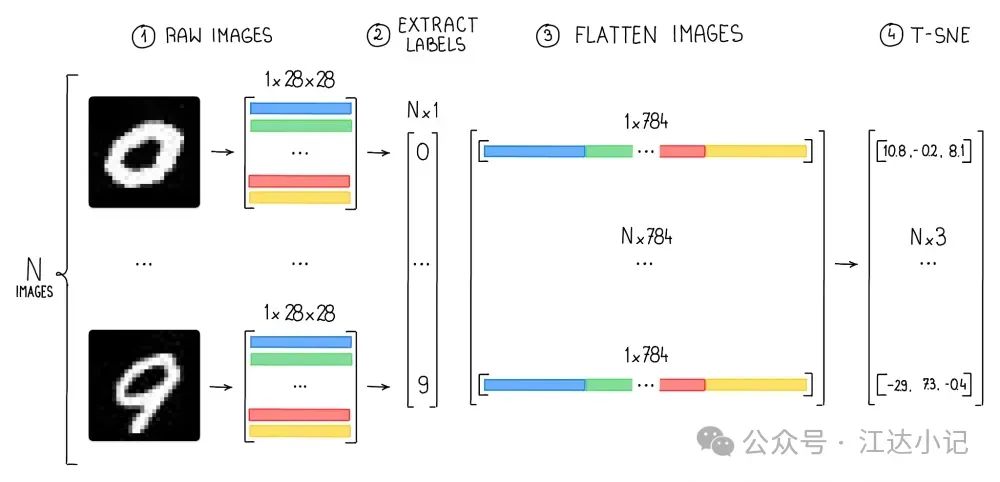
使用像素亮度时处理阶段的张量维度的示意图。
为了实现这一目标,我们首先需要加载每个类别的图像,并将数据重塑成可以被t-SNE使用的格式(一个具有784个特征的二维NumPy数组)。
可视化高维数据
可视化和处理高维数据可能具有挑战性,因为随着维度的增加,理解数据的底层结构和关系变得越来越困难。降维技术,如t-SNE和UMAP,是简化这些复杂数据集的重要工具,使它们更易于管理和解释。
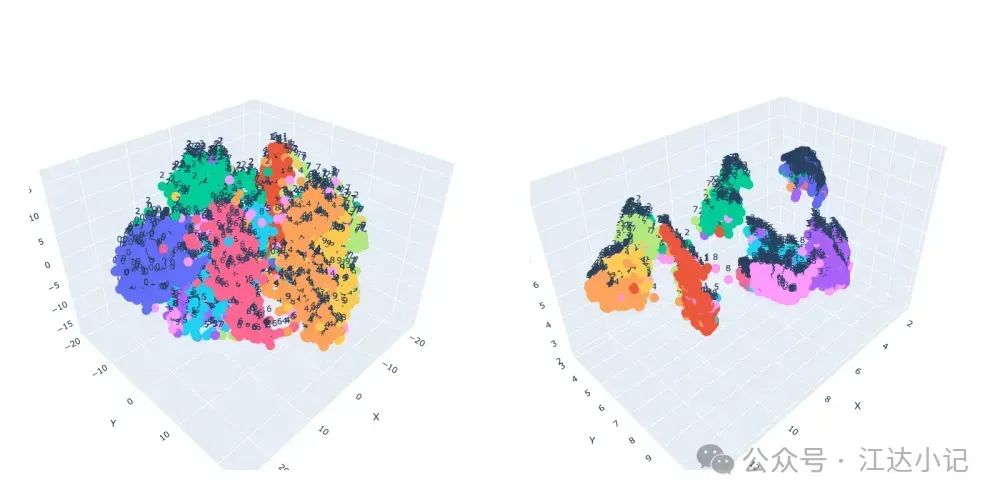
展示t-SNE和UMAP等方法的工作原理的示意图。
如果两张图像都描绘了数字6,并且书写风格相似,那么它们在低维空间中将被表示为彼此靠近的点。这是因为这些技术旨在保留原始高维空间中数据点之间的相对相似性。因此,表示相似图像的点将彼此靠近。相反,显示不同数字(如1和8)的图像将被表示为在降维空间中相距较远的点。
t-SNE与UMAP
t-SNE和UMAP都是用于高维数据降维和可视化的流行技术。然而,它们之间存在一些关键差异。UMAP以其计算效率和可扩展性而闻名,这使得它能够比t-SNE更快地处理更大的数据集。在我们使用5,000张图像的简单测试中,UMAP的速度几乎是t-SNE的3倍。
1 | from sklearn.manifold import TSNEprojections = TSNE(n_components = 3).fit_transform(train) |
from umap import UMAPprojections = umap.UMAP(n_components=3).fit_transform(train)
1 |
|
import clipdevice = “cuda” if torch.cuda.is_available() else "cpu"model, preprocess = clip.load(“ViT-B/32”, device=device)image_path = "path/to/your/image.png"image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)with torch.no_grad(): embeddings = model.encode_image(image)
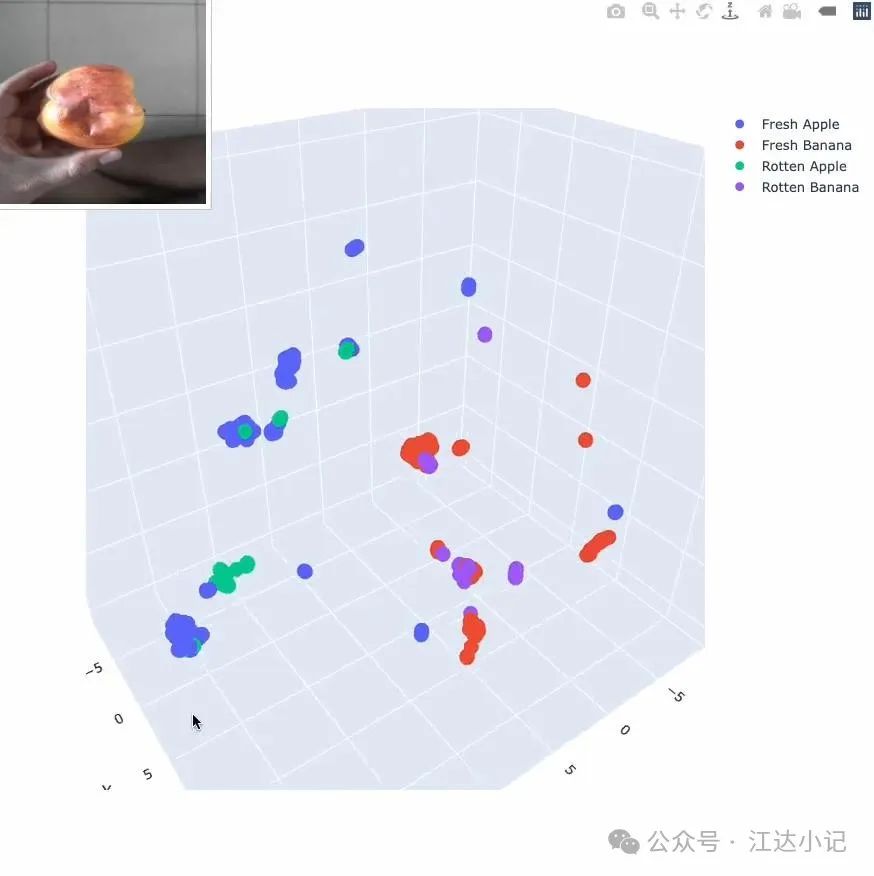
## 使用嵌入识别相似图像
嵌入还可以用于识别相似或近乎相似的图像。通过比较嵌入的向量,我们可以使用余弦值来衡量两张图像之间的相似性。这个值的范围是从-1到1,在计算机视觉向量分析的上下文中,余弦值为1表示高度相似,值为-1表示不相似,值为0表示正交性,即图像之间没有共同特征。通过利用这一见解,我们可以根据余弦值有效地识别和分组相似图像,同时区分那些不相关或正交的图像。

使用CLIP嵌入和三角学进行图像相似性分析的示意图。
在搜索相似图像的过程中,我们首先将图像嵌入结构化为一个二维NumPy数组,其维度为N×M,其中N表示分析的图像数量,M表示单个嵌入向量的大小——在我们的情况下是768。在计算余弦相似性之前,对这些向量进行归一化是至关重要的。
向量归一化是将向量缩放为单位长度的过程,**这确保了余弦相似性仅衡量向量之间的角度距离,而不是它们的大小**
。有了归一化的向量,我们可以高效地使用向量化计算所有图像对的余弦相似性,从而有效地识别和分组相似图像。
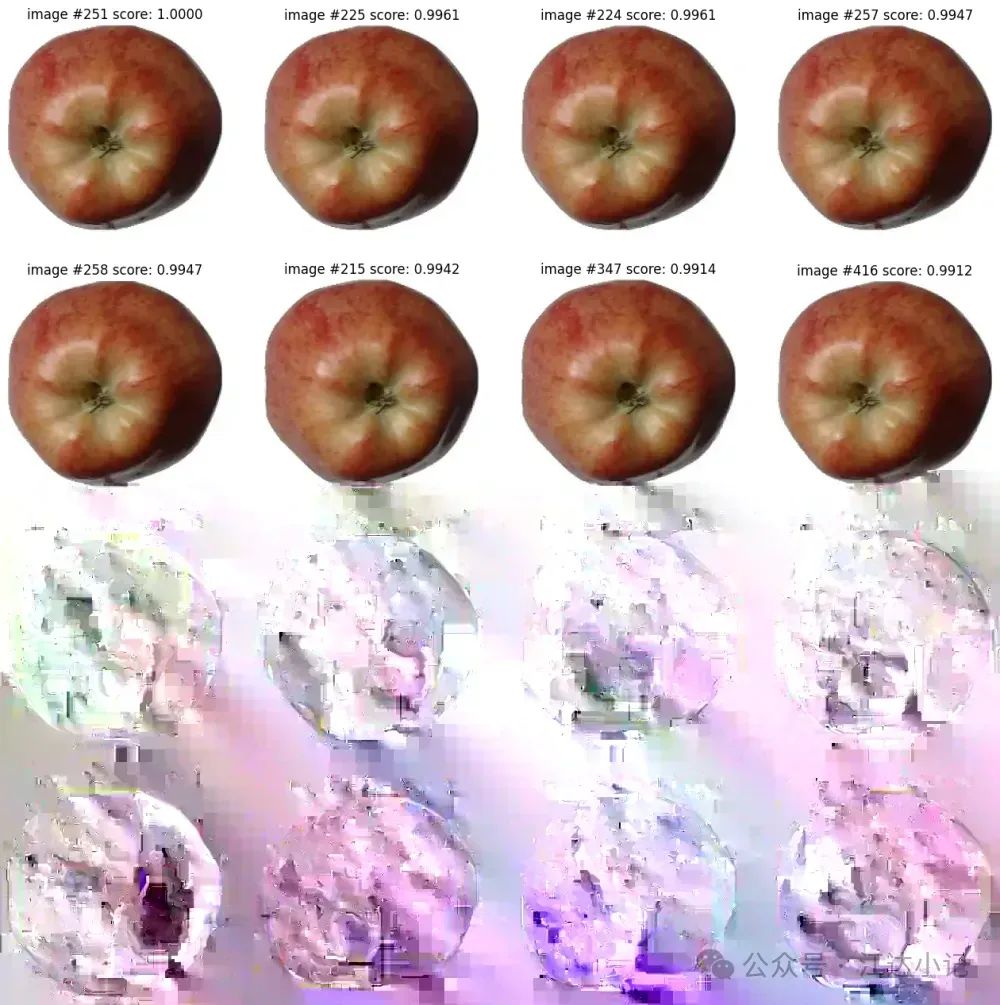
通过向量余弦找到的最相似图像组的示意图。
## 结论
OpenAI CLIP嵌入是计算机视觉领域中一个极其强大的工具。随着我们不断前进,我们计划探索更多的用例,测试新的模型(不仅仅是CLIP),并深入研究嵌入的世界,以帮助你在这个快速发展的计算机视觉领域中解锁更多的可能性。请继续关注未来的文章,我们将继续突破边界并揭示利用嵌入力量的新方法。
