什么是检索增强生成(RAG)?
检索增强生成(Retrieval Augmented Generation,简称RAG)是一种架构,它在生成式人工智能应用的大型语言模型(LLM)执行任务时,为其提供最相关且具有上下文重要性的专有、私有或动态数据,以增强其准确性和性能。
RAG在人工智能/LLM中的作用
RAG是一种利用数据库检索技术,在生成时为用户提供与上下文最相关的匹配结果的方法。基于大型语言模型(LLM)构建的产品,如OpenAI的ChatGPT和Anthropic的Claude,虽然功能强大,但也存在一些缺陷:
-
静态性
——LLM是“冻结在时间中”的,缺乏最新信息。更新其庞大的训练数据集是不切实际的。 -
缺乏特定领域的知识
——LLM是为通用任务训练的,这意味着它们不了解您公司的私有数据。 -
黑箱操作
——很难理解LLM在得出结论时考虑了哪些来源。 -
生产成本高且效率低
——很少有组织具备生产并部署基础模型所需的财力和人力。
不幸的是,这些问题会影响利用LLM的生成式人工智能应用的准确性。对于任何要求高于普通聊天机器人演示的商业应用,如果仅使用未经修改的LLM(除了提示之外),在上下文依赖的任务中表现会很差,例如帮助客户预订下一趟航班。
本文将探讨为什么检索增强生成是解决这些缺陷的首选方法,深入探讨RAG的工作原理,并解释为什么大多数公司使用RAG来提升其生成式人工智能应用的性能。
Pinecone是开发者最喜欢的矢量数据库,它快速且易于使用,适用于任何规模。
LLM停留在特定时间,但RAG可以将其带入现在
ChatGPT的训练数据“截止点”是2021年9月。如果您问ChatGPT上个月发生的事情,它不仅无法正确回答您的问题,还可能会编造一个听起来非常有说服力的谎言。我们通常称这种行为为“幻觉”。
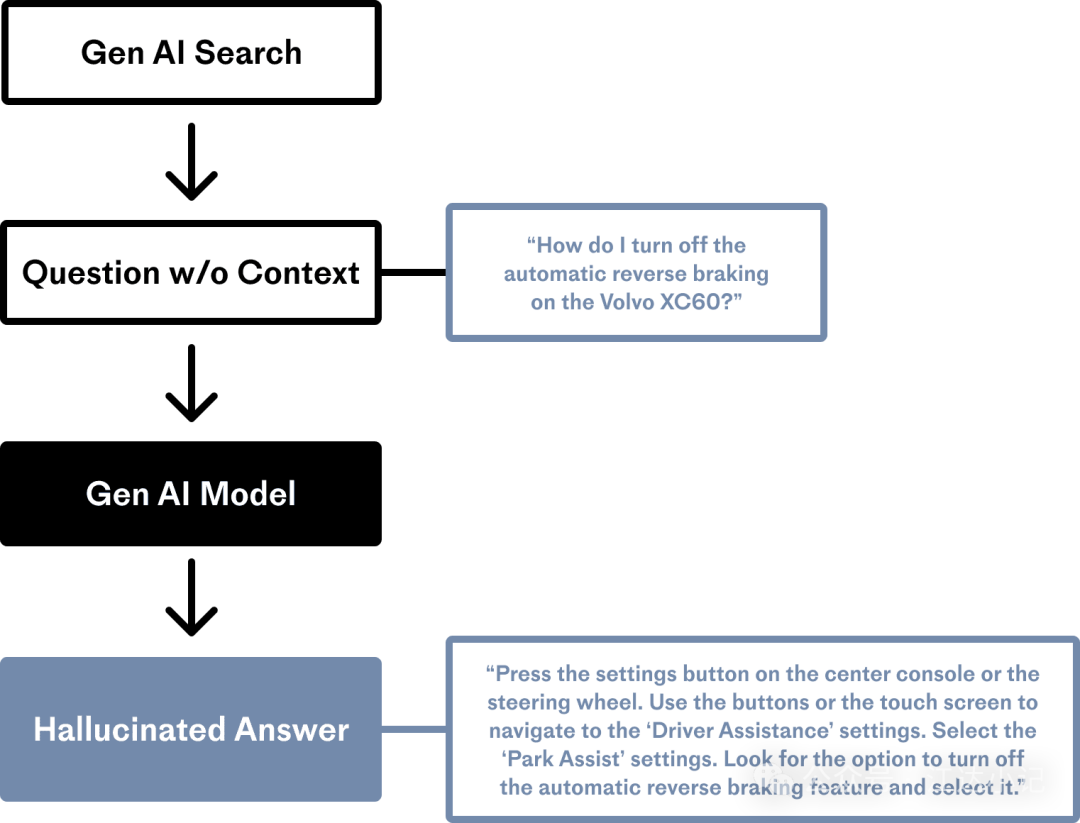
在上面的例子中,LLM缺乏关于沃尔沃XC60的具体信息。尽管LLM不知道如何关闭该车型的倒车制动,但它仍然尽力完成生成任务,生成一个语法上看起来很合理的答案——但不幸的是,这个答案是完全错误的。
LLM之所以感觉如此聪明,是因为它们接触到了大量的人类创造性输出——包括整个公司的开源代码、图书馆的书籍、一生的对话、科学数据集等,但关键在于,这些核心训练数据是静态的。
在OpenAI于2021年完成ChatGPT背后的基础模型(FM)的训练后,它没有收到关于世界的新信息;它仍然对重大世界事件、天气系统、新法律、体育赛事的结果以及上图中最新汽车的操作程序一无所知。
RAG为您的生成式人工智能应用提供最新信息和特定领域的数据
检索增强生成意味着从外部数据库中检索最新或特定上下文的数据,并在生成响应时将其提供给LLM,从而解决这个问题。您可以存储专有业务数据或有关世界的信息,并让您的应用在生成时为LLM检索这些数据,减少幻觉的可能性。结果是您的生成式人工智能应用的性能和准确性明显提升。
LLM缺乏私有数据的上下文——在被问及特定领域或公司问题时会导致幻觉
当前LLM的第二个主要缺点是,尽管它们的基础知识库令人印象深刻,但它们不知道您的业务细节、您的要求、您的客户群体或您的应用运行的上下文——例如您的电子商务商店。
RAG通过在生成时为您的生成式人工智能应用的LLM提供额外的上下文和事实信息来解决第二个问题:从客户记录到剧本中的对话段落,再到产品规格和当前库存,再到音频如语音或歌曲。LLM使用这些提供的内容生成有根据的答案。
检索增强生成允许生成式人工智能引用来源并提高可审计性
除了解决最新信息和特定领域数据的问题外,RAG还允许生成式人工智能应用提供其来源,就像研究论文会为其发现中使用的关键数据提供引用一样。
想象一个为法律行业服务的生成式人工智能应用,帮助律师准备论点。该应用最终会以最终输出的形式呈现其建议,但RAG使其能够提供其在提出建议时使用的法律先例、地方法律和证据的引用。
RAG使生成式人工智能应用的内部工作原理更容易被审计和理解。它允许最终用户直接跳转到LLM在创建答案时使用的相同源文档。
为什么RAG是从成本效益角度出发的首选方法?
除了RAG之外,还有三种主要方法可以提高生成式人工智能应用的性能。让我们来审视一下它们,以了解为什么RAG仍然是大多数公司今天选择的主要路径。
创建自己的基础模型
OpenAI的Sam Altman估计,训练ChatGPT背后的基础模型大约花费了1亿美元。
并不是每个公司或模型都需要如此巨大的投资,但ChatGPT的价格标签强调了生产复杂模型的成本是当今技术面临的真正挑战。
除了原始计算成本外,您还将面临稀缺人才问题:您需要专门的机器学习博士、顶尖的系统工程师和高技能的运维人员来解决生产这种模型的许多技术挑战,而世界上其他人工智能公司也在争夺这些稀缺人才。
另一个挑战是获取、清理和标记生产基础模型所需的数据库。例如,假设您是一家法律发现公司,正在考虑训练模型以回答有关法律文件的问题。在这种情况下,您还需要法律专家花费数小时标记训练数据。
即使您有足够的资金,能够组建合适的团队,获取并标记足够的数据,并克服将模型托管在生产环境中的许多技术障碍,也无法保证成功。这个行业已经见证了许多雄心勃勃的人工智能初创公司的兴衰,我们预计还会有更多失败。
微调:将基础模型适配到您的领域数据
微调是使用新数据重新训练基础模型的过程。它当然比从头开始构建基础模型更便宜,但这种方法仍然存在创建基础模型的许多缺点:您需要罕见且深厚的专业知识和足够的数据,而将模型托管在生产环境中的成本和技术复杂性并没有消失。
微调不再是提高LLM输出的实用方法,因为LLM现在可以与矢量数据库配对以检索上下文。一些LLM提供商,如OpenAI,不再支持其最新一代模型的微调。
微调是一种过时的提高LLM输出的方法。它需要反复的、昂贵的和耗时的主题专家标记工作以及对质量漂移的持续监控,这是由于缺乏定期更新或数据分布的变化而导致模型准确性出现不期望的偏差。
如果您的数据随时间变化,即使是经过微调的模型的准确性也会下降,需要更多昂贵的和耗时的数据标记、持续的质量监控和重复的微调。
想象一下每次销售一辆汽车时都要更新模型,以便您的生成式人工智能应用拥有最新的库存数据。
提示工程不足以减少幻觉
提示工程意味着测试和调整您提供给模型的指令,试图引导它按照您的意愿行事。
这也是提高生成式人工智能应用准确性的最便宜选项,因为您可以通过简单的代码更改快速更新提供给生成式人工智能应用LLM的指令。
它可以优化LLM返回的响应,但无法为其提供任何新的或动态的上下文,因此您的生成式人工智能应用仍然缺乏最新上下文,容易出现幻觉。
深入了解检索增强生成的工作原理
我们已经讨论了RAG如何在生成时通过“上下文窗口”将您特定领域的数据库中的额外相关内容传递给LLM,与原始提示或问题一起传递。
LLM的上下文窗口是它在某一时刻的视野范围。RAG就像为LLM举起一张提示卡,上面写着关键要点,帮助它产生更准确的回答,融入关键数据。
要理解RAG,我们首先需要了解语义搜索,它试图找到用户查询的真实含义,并检索相关信息,而不是简单地匹配用户查询中的关键词。语义搜索旨在提供更符合用户意图的结果,而不仅仅是他们的确切词汇。

使用嵌入模型将您特定领域的专有数据转换为矢量数据库。
该图显示了如何使用您的特定领域、专有数据创建矢量数据库。要创建矢量数据库,您需要通过嵌入模型将数据转换为矢量。
嵌入模型是一种LLM,它将数据转换
为矢量:数字数组或数字组。在上例中,我们正在将包含最新沃尔沃汽车操作的用户手册转换为矢量,但您的数据可以是文本、图像、视频或音频。
最重要的是要理解,矢量代表输入文本的含义,就像另一个人在听到您说出文本时会理解其本质一样。我们将数据转换为矢量,以便计算机可以根据存储数据的数值表示搜索语义相似的项目。
接下来,您将矢量放入矢量数据库,如Pinecone。Pinecone的矢量数据库可以在不到一秒钟的时间内搜索数十亿个项目以找到相似匹配项。
记住,您可以创建矢量,将矢量摄入数据库,并实时更新索引,从而解决LLM在生成式人工智能应用中的最新性问题。
例如,您可以编写代码,自动为您的最新产品创建矢量,然后在每次推出新产品时将它们插入索引。然后,您公司的支持聊天机器人应用可以使用RAG检索有关产品可用性的最新信息以及它正在与之聊天的当前客户的数据。
矢量数据库允许您使用自然语言查询数据,这对于聊天界面来说是理想的
现在您的矢量数据库包含了目标数据的数值表示,您可以执行语义搜索。矢量数据库在语义搜索用例中表现出色,因为最终用户通常使用模糊的自然语言形成查询。
语义搜索通过将用户的查询转换为嵌入,并使用矢量数据库搜索相似条目来工作
让我们看看在能够动态注入上下文时,检索增强生成示例会发生什么:

检索增强生成(RAG)使用语义搜索检索相关且及时的上下文,LLM使用这些上下文产生更准确的回答。
您最初将专有数据转换为嵌入。当用户发出查询或问题时,您将他们的自然语言搜索词转换为嵌入。
您将这些嵌入发送到矢量数据库。数据库执行“最近邻”搜索,找到最接近用户意图的矢量。当矢量数据库返回相关结果时,您的应用通过其上下文窗口将它们提供给LLM,提示它执行其生成任务。
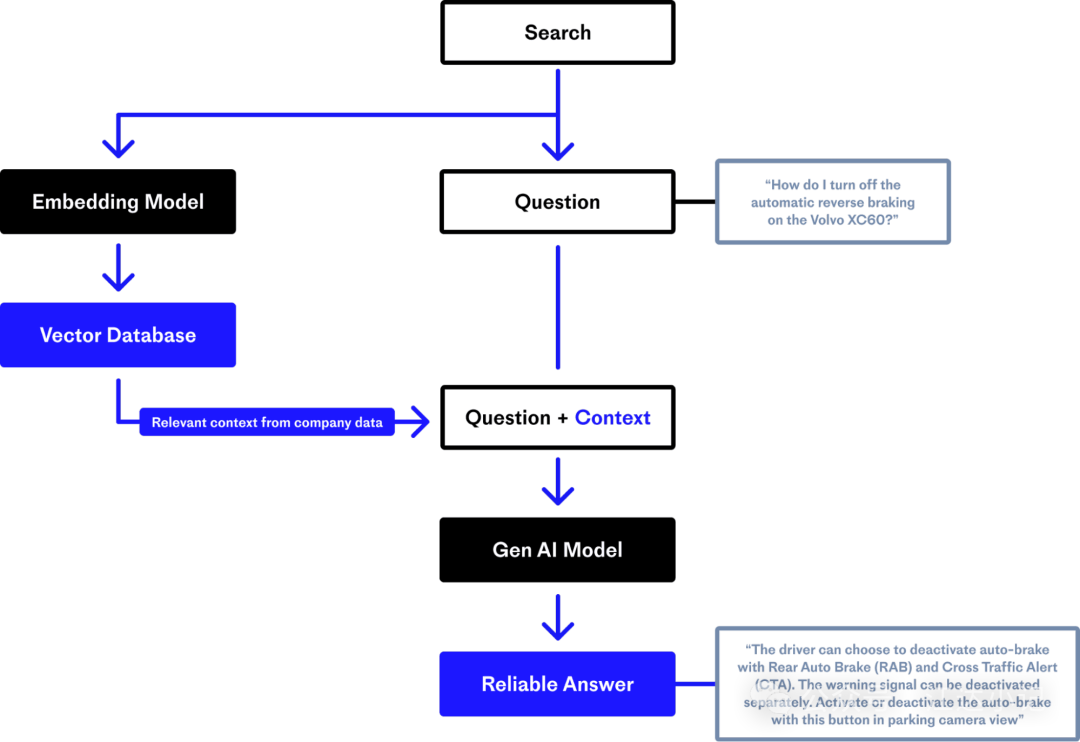
检索增强生成通过LLM的上下文窗口提供特定领域的信息,减少了幻觉的可能性。
由于LLM现在可以访问您的矢量数据库中最相关且具有基础性的事实,您的RAG应用可以为用户提供准确的答案。RAG减少了幻觉的可能性。
矢量数据库可以支持更高级的搜索功能
语义搜索功能强大,但还可以更进一步。例如,Pinecone的矢量数据库支持混合搜索功能,这是一种考虑查询语义和关键词的检索系统。
RAG是提高生成式人工智能应用性能的最具成本效益、最容易实施且风险最低的路径
语义搜索和检索增强生成提供了更相关的生成式人工智能回答,转化为最终用户的卓越体验。与构建自己的基础模型、微调现有模型或仅进行提示工程相比,RAG同时以更具成本效益和更低风险的方式解决了最新性和特定上下文的问题。
其主要目的是提供对需要访问私有数据才能正确回答的问题的上下文敏感、详细的答案。
