互联网黑话“打平”是什么意思
一、消除差异或冗余
- 跨部门协作
:指通过协调或调整资源,使不同团队、部门间的流程、数据或目标达成统一,消除冗余或冲突状态。
示例
:产品与运营部门需求冲突时,需通过“打平”双方资源分配以推进项目。
- 数据一致性
:在技术场景中,指对异构数据进行格式统一或逻辑对齐,确保系统间可兼容。
示例
:产品与运营部门需求冲突时,需通过“打平”双方资源分配以推进项目。
当前端开发人员在本地进行调试时,他们通常会与本地主机(localhost)进行交互,只需运行 npm run
命令,即可在浏览器中打开他们的网页,地址栏会显示类似
http://localhost
:xxx/index.html 的内容。
许多人可能会在没有深思两者区别的情况下使用它。
本地主机(localhost)是一个域名,本质上与用于互联网访问的域名没有区别,只是更容易记住。
本地主机(localhost)的范围仅限于本地计算机——它的名称已经说明了这一点:“本地”指的是在本地范围内的内容。
项目地址:
https://github.com/microsoft/OmniParser
OmniParser
用于将用户界面截图解析为结构化且易于理解的元素,下面介绍一下怎么在mac上部署使用这个屏幕解析器
首先克隆代码库,然后安装环境:
1 | git clone https://github.com/microsoft/OmniParser.git |
Ollama 是一个专为本地化部署和运行大型语言模型(LLM)设计的开源框架,其核心功能与特点如下:
便捷部署
提供预训练模型库(如 Llama、Mistral、Gemma 等),用户可直接调用。
支持从 PyTorch、Safetensors 等框架导入自定义模型,并允许调整参数(如 temperature
)进行个性化配置。
轻量化与扩展性
以轻量级架构实现低资源占用,同时具备良好的硬件适应性,适用于不同规模项目。
开发支持
提供简洁的 API,便于开发者创建、管理和交互模型实例。
本地实验与开发
:研究人员和开发者可快速测试、微调模型(如 Llama 3、DeepSeek),构建个性化 AI 助手。
私有化模型部署
:支持在企业内部服务器运行模型,但需注意部分版本存在未加密传输等安全风险。
项目地址:
https://github.com/philippgille/chromem-go
一个可嵌入的 Go 向量数据库,具有类似 Chroma 的接口和零第三方依赖。支持内存存储,并可选持久化。
因为 chromem-go
是可嵌入的,所以它允许你在 Go 应用程序中添加检索增强型生成(RAG)和类似的基于嵌入的特性,而无需运行单独的数据库。这就好比使用 SQLite 而不是 PostgreSQL/MySQL 等。
它并不是一个用于连接 Chroma 的库,也不是 Chroma 在 Go 中的重新实现。它是一个独立的数据库。
它的重点不是规模(数百万文档)或功能数量,而是针对最常见的用例的简单性和性能。在 2020 年的中端英特尔笔记本 CPU 上,你可以查询 1,000 个文档仅需 0.3 毫秒,100,000 个文档仅需 40 毫秒,且内存分配很少且很小。详细信息请查看基准测试。
检索增强生成(Retrieval Augmented Generation,简称RAG)是一种架构,它在生成式人工智能应用的大型语言模型(LLM)执行任务时,为其提供最相关且具有上下文重要性的专有、私有或动态数据,以增强其准确性和性能。
RAG是一种利用数据库检索技术,在生成时为用户提供与上下文最相关的匹配结果的方法。基于大型语言模型(LLM)构建的产品,如OpenAI的ChatGPT和Anthropic的Claude,虽然功能强大,但也存在一些缺陷:
静态性
——LLM是“冻结在时间中”的,缺乏最新信息。更新其庞大的训练数据集是不切实际的。
缺乏特定领域的知识
——LLM是为通用任务训练的,这意味着它们不了解您公司的私有数据。
黑箱操作
——很难理解LLM在得出结论时考虑了哪些来源。
生产成本高且效率低
——很少有组织具备生产并部署基础模型所需的财力和人力。
不幸的是,这些问题会影响利用LLM的生成式人工智能应用的准确性。对于任何要求高于普通聊天机器人演示的商业应用,如果仅使用未经修改的LLM(除了提示之外),在上下文依赖的任务中表现会很差,例如帮助客户预订下一趟航班。
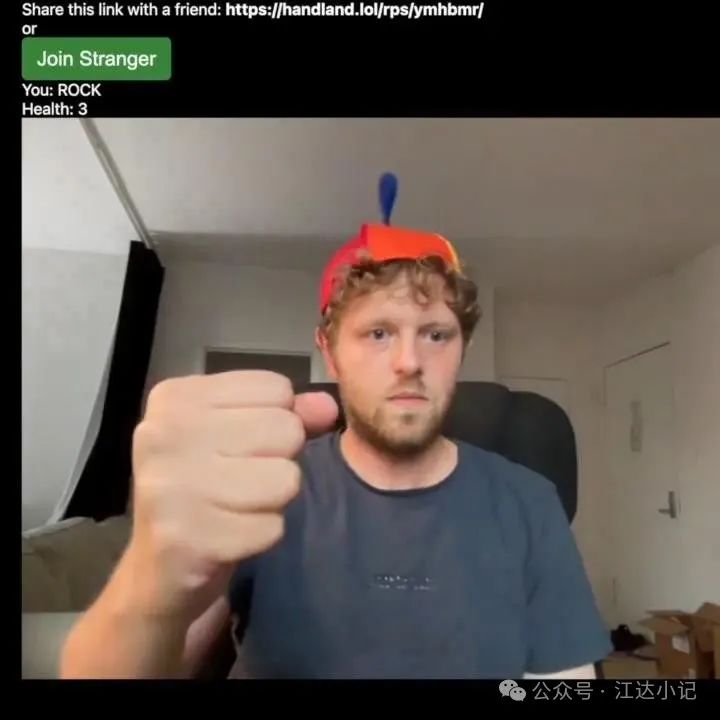
这篇文章是一个模板,展示了如何利用人工智能或计算机视觉制作多人游戏,比如“石头、剪刀、布”,这些游戏涉及手部和身体的动作。
包含的多人游戏:
代码库目前包含三个完整的双人游戏:
石头、剪刀、布
对视比赛
007(对峙或阻挡、重新装填、射击和霰弹枪)——如何玩
计算机视觉通过使机器能够看到、理解和对视觉数据采取行动,正在改变各个行业的面貌。从优化生产线到增强工作场所的安全性,再到监控交通基础设施,人工智能驱动的视觉系统正在大规模推动效率、准确性和自动化的提升。
还不确定计算机视觉如何对您有所帮助?在本指南中,我们分解了 50 个企业正在部署计算机视觉的实际用例。了解如何自动化分类、计数、缺陷检测、读取发票、创建零售陈列图、查找缺失产品、跟踪品牌标志、检测火灾等。
这些示例展示了视觉人工智能如何改变物流、医疗保健、农业、零售等行业的未来,并影响我们的日常生活。
让我们深入了解计算机视觉如何通过实际示例塑造自动化的未来。
翻译自
https://blog.roboflow.com/embeddings-clustering-computer-vision-clip-umap/
嵌入在自然语言处理(NLP)领域已经成为一个热门话题,并且在计算机视觉中也越来越受到关注。这篇博客文章将通过研究图像聚类、评估数据集质量和识别图像重复项,探讨嵌入在计算机视觉中的应用。
我们创建了一个Google Colab笔记本,你可以在阅读这篇博客文章的同时在另一个标签页中运行它,让你能够实时实验和探索这里讨论的概念。让我们开始吧!
在我们跳到涉及OpenAI CLIP嵌入的例子之前,让我们先从一个不太复杂的例子开始——根据像素亮度对MNIST图像进行聚类。
在计算机视觉领域,有一个核心概念:让计算机能够理解视觉输入。这一概念可以分解为许多任务:识别图像中的物体、对图像进行聚类以找出异常值、创建用于搜索大量视觉数据的系统等。图像嵌入(embedding)是许多视觉任务的核心,从聚类到图像比较,再到为大型多模态模型(LMMs)提供视觉输入,都离不开它。
在本指南中,我们将介绍什么是图像嵌入、它们如何被使用,以及 CLIP,这是一个流行的计算机视觉模型,你可以用它来生成图像嵌入,从而构建一系列应用程序。
不再多说,让我们开始吧!
图像嵌入是对图像的数值表示,它编码了图像内容的语义。嵌入是通过计算机视觉模型计算得出的,这些模型通常使用大量成对的文本和图像数据进行训练。这种模型的目标是构建图像与文本之间关系的“理解”。